
C vs Go vs pypy vs Python vs Javascript V8
I love to perform benchmarking tests and try to optimise algorithms, or compare implementations in different languages. This time I compared Go, C, pypy, Python and JS with a simple loop which sums all numbers between 1 and 10.000.000
To my big surprise, at first the winner wasn’t C but Go. I had no idea why at first but eventually I found out.
Specs
MacBook Pro (Retina, 13-inch, Early 2015)
Processor 2.7 GHz Intel Core i5
Memory 8 GB 1867 MHz DDR3
C compiler: clang-700.0.75
Go version go1.5.1 darwin/amd64
PyPy 2.6.0 with GCC 4.2.1 Compatible Apple LLVM 5.1 (clang-503.0.40)
Python 2.7.10
Node v0.12.6
This is the C code
#include <stdio.h>
int main ()
{
long a;
long sum;
/* for loop execution */
for( a = 0; a < 10000000; a++ )
{
sum += a;
}
printf("sum: %ld\n", sum);
return 0;
}Go
package main
import "fmt"
func main() {
sum := 0
for i := 0; i < 10000000; i++ {
sum += i
}
fmt.Println(sum)
}Python/pypy
sum = 0
for i in range(10000000):
sum+=i
print(sum)As you can see, C is pretty damn fast, it takes only 0.03 seconds to sum up everything.

Python takes 1.75 seconds

Pypy took 0.26 seconds the first time

The second time it took only 0.101 which is only 3 times slower than the C implementation

But the indisputable winner was Go which took only 0.010 seconds, 3x faster than C.
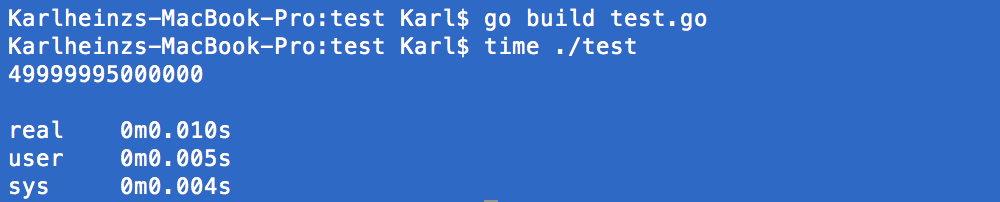
Update 1
I added a test with NodeJs
var sum = 0;
for (var i = 0; i < 10000000; i++) {
sum+=i;
}
console.log(sum);Amazing, JS really seems to be the fastest interpreted language (I know).. just 0.077 seconds! 2.4 times slower than unoptimised C and about 31% faster than pypy

###Update 2 Problem solved As pointed out on Reddit and the comments, using CFLAGS to activate code optimisation of the compiler increases the speed of C considerably. I also had to initialise the sum variable because otherwise it returned the wrong result. This is how I compiled
$ gcc -O3 -march=native loop_sum.c -o loop_sum#include <stdio.h>
int main ()
{
long a;
long sum = 0;
/* for loop execution */
for( a = 0; a < 10000000; a++ )
{
sum += a;
}
printf("sum: %ld\n", sum);
return 0;
}Now the code runs 5x faster than C without using CFLAGS and 40% faster than Go.

####Update 3: Changed the code with command line args for further testing
To make sure that the output isn’t just a precomputed constant value made at compile time, I’ve adapted the code for command line arguments. Now I can pass any number I want, the tests were consistent with the previous measurements.
C with command line argument
#include <stdio.h>
#include <stdlib.h>
main(int argc, char *argv[])
{
int arg1 = 1;
arg1 = atoi(argv[1]);
long a;
long sum = 0;
/* for loop execution */
for( a = 0; a < arg1; a++ )
{
sum += a;
}
printf("sum: %ld\n", sum);
return 0;
}The C assembly code I got with the following command is just 40 lines long
$ gcc loop_sum.c -S .section __TEXT,__text,regular,pure_instructions
.macosx_version_min 10, 10
.globl _main
.align 4, 0x90
_main: ## @main
.cfi_startproc
## BB#0:
pushq %rbp
Ltmp0:
.cfi_def_cfa_offset 16
Ltmp1:
.cfi_offset %rbp, -16
movq %rsp, %rbp
Ltmp2:
.cfi_def_cfa_register %rbp
movq 8(%rsi), %rdi
callq _atoi
xorl %esi, %esi
testl %eax, %eax
jle LBB0_2
## BB#1: ## %.lr.ph
movslq %eax, %rcx
leaq -1(%rcx), %rax
leaq -2(%rcx), %rdx
mulq %rdx
shldq $63, %rax, %rdx
leaq -1(%rcx,%rdx), %rsi
LBB0_2:
leaq L_.str(%rip), %rdi
xorl %eax, %eax
callq _printf
xorl %eax, %eax
popq %rbp
retq
.cfi_endproc
.section __TEXT,__cstring,cstring_literals
L_.str: ## @.str
.asciz "sum: %ld\n"
.subsections_via_symbolsGo with command line argument
package main
import "os"
import "fmt"
import "strconv"
func main() {
arg := os.Args[1]
n, e := strconv.Atoi(arg)
if e != nil {
fmt.Println(e)
}
sum := 0
for i := 0; i < n; i++ {
sum += i
}
fmt.Println(sum)
}The Go assembly code is 161.021 lines long which must be due to the static linking of Go.
$ otool -tvV loop_sum_go C

What also is interesting is that it doesn’t seem to matter much if I pass in bigger numbers, here trying with 1.000.000.000

Go

Go takes considerably longer with 1.000.000.000
####To sum it up
I noticed that the optimised code executes in constant time, no matter what number I throw at it. Suspecting that the compiler did a trick there, as mentioned I changed the code to pass the number as command line parameter. Doing so I made sure that the result itself wasn’t precomputed. Despite that the response time remained constant, so the only remaining logical explanation was that the compiler used math to compute the sum and it was confirmed in this neat blogpost. The nifty Clang compiler uses sum of an arithmetic sequence formula to get away with executing the task without doing the heavy lifting of the loop. Clever, but this shows that it is really hard to do fair benchmarks.
Formula used by Clang to thrash the loop sum’s
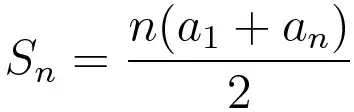
After all, it seems that Go is faster at running the loop. I haven’t confirmed this in Go’s assembly code (perhaps someone can make a blogpost about that too :) ) but I think I can safely assume so because Go’s response time is proportional to the input number.
I will certainly take a closer look at this so stay tuned.
Comments